Scoring & Relevantie in Solr
Onlangs liet ik jullie kennismaken met Apache Solr, het open-source zoekplatform dat we vaak gebruiken voor onze projecten. Zoals beloofd ga ik vandaag dieper in op de relevantie in Solr.
Score
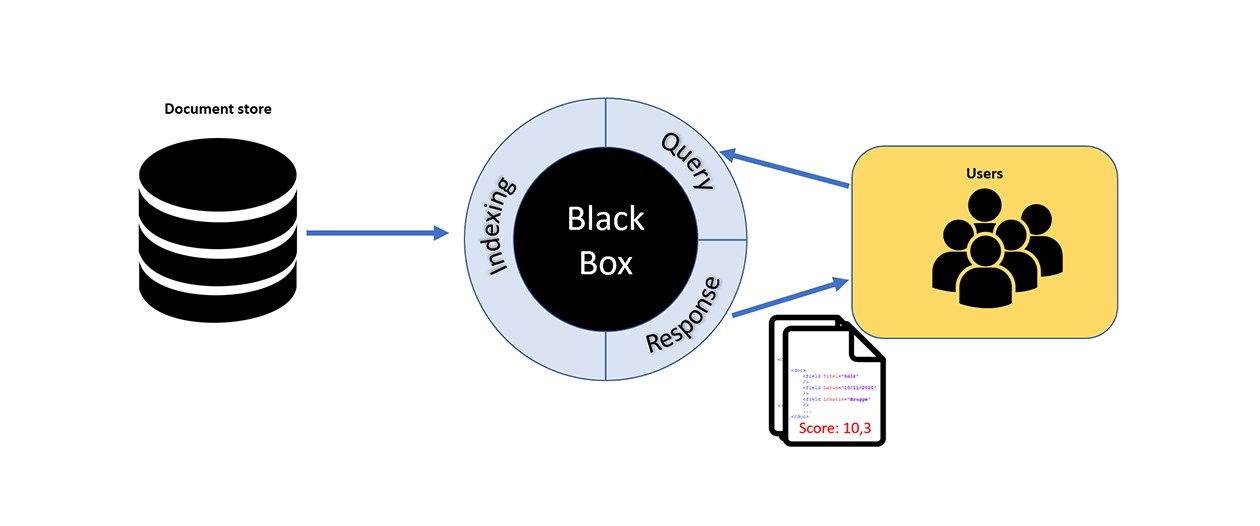
Wanneer de Solr instantie geconfigureerd is, kunnen we zoekopdrachten uitvoeren. Bij zo’n query wordt het aantal kandidaat-documenten gereduceerd door een booleaanse test toe te passen: komt het document overeen met de zoekopdracht?
Wanneer de response van de zoekopdracht een reeks documenten bevat, krijgt elk document een score en worden ze vervolgens hierop gerangschikt. Solr baseert zich bij het zoeken achter de schermen namelijk op een ranking score. Hoe hoger de score die bij een document hoort, hoe hoger het document in de resultatenlijst komt.
Solr maakt gebruik van het Okapi BM25 ranking algoritme (Best Match 25) om een score toe te kennen aan een document.

Het algoritme bestaat uit een aantal factoren:
- Term Frequency (TF): hoe vaak komt de term voor in een document? Hoe meer, hoe relevanter.
- Inverse Document Frequency (IDF): in hoeveel documenten komt de term voor? In hoe meer documenten de term voorkomt, hoe minder relevant hij is.
- Document length: hoe korter de tekst waarin de term in voorkomt, hoe relevanter de term is.
Relevantie
Solr maakt standaard dus gebruik van een stevig ranking mechanisme. De score van een document wordt bepaald op basis van de veldovereenkomsten van de opgegeven zoekopdracht. Maar dit betekent niet dat het document daarom relevant is voor jouw gebruikers.
Per business case wil je wellicht andere resultaten ontvangen, afhankelijk van de context zoals de gebruiker die de zoekopdracht lanceert, de periode, de zoektermen, populariteit… Om de relevantie te beïnvloeden of bij te sturen voorziet Solr een aantal technieken. Dit noemen we boosten.
Boosten in Solr betekent dat je de query en index aanpast/aanvult met extra parameters om de gebruiker te laten vinden waarnaar hij op zoek is.Simpel gesteld is het je query aanvullen met relevante parameters en die een gewicht toekennen. Maar de zoektocht naar die parameters en het gewenste gewicht heeft wel wat voeten in de aarde.
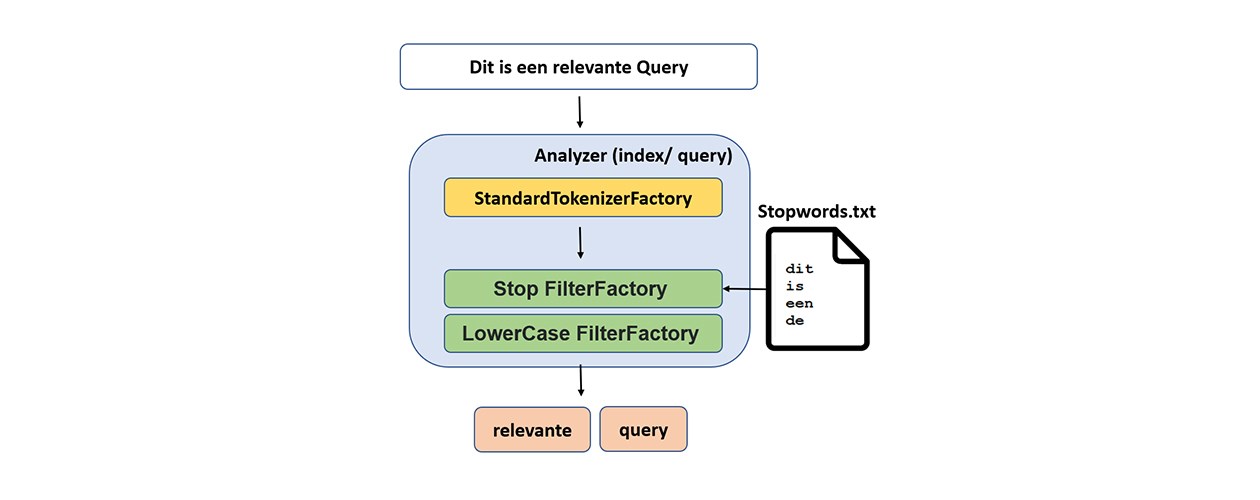
Hoe werkt dit boosten precies? Wanneer een zoekopdracht naar Solr wordt verstuurd, wordt deze door een queryparser gehaald. Die deelt de query vervolgens op in stukken en stuurt ze door naar verschillende analyzers (afhankelijk van het .xml schema en de velden waarop de query wordt uitgevoerd). Net als bij het indexeren wordt de tekst per veld door de bijhorende analyzer gehaald. Het resultaat is een tokenstream om mee op zoek te gaan in de inverted index. De boosting regels die mee opgegeven werden in de query, worden ten slotte in rekening gebracht om de bijhorende documenten een bepaalde score/relevantie toe te kennen.
Standaard zijn er 3 queryparsers aanwezig:
- Lucene Query Parser
- DisMax Query Parser
- eDisMax Query Parser
Elke queryparser heeft zijn eigen syntax en bevat andere eigenschappen en bijhorende parametersets. De eDisMax is de meest uitgebreide parser en bevat ook de eigenschappen van de lucene en dismax parsers.
Enkele voorbeelden van query boosting:
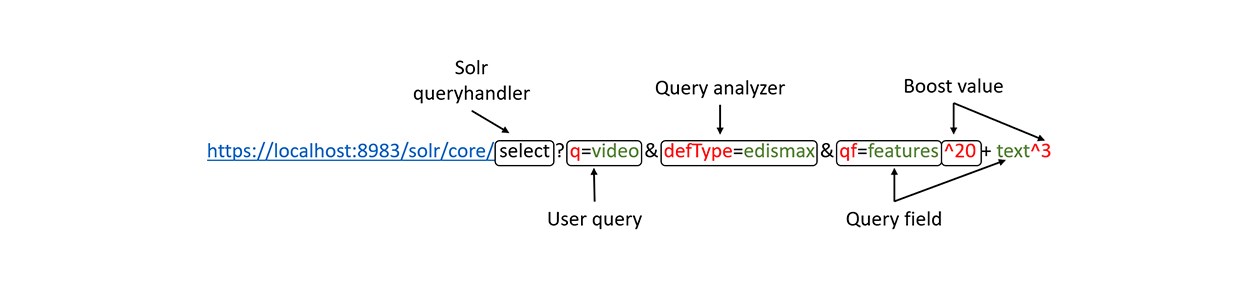
- Term boosting: q=mars^2.0
- Field boosting: defType=edismax&q=mars&qf=titel^3.0
- Boost query parameter: defType=edismax&q=mars&bq=cat:planet^2.0
- Proximity boosting: (afstand tussen woorden): “Mars Pluto”~4
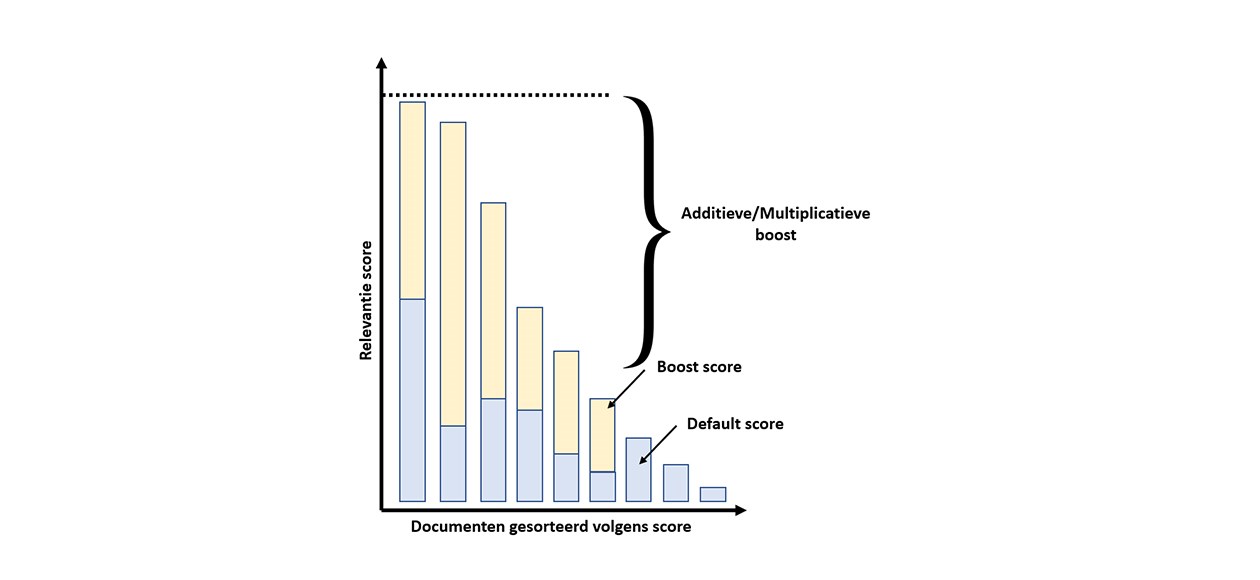
Sommige boostfuncties zijn additief, andere zijn multiplicatief.
- Additief = BM25 score + opgegeven boost value
- Multiplicatief = BM25 score x opgegeven boost value
Het is afwegen welk type en gewicht het meest geschikt zijn. Meestal zijn multiplicatieve boostfuncties aangewezen omdat die het meest doorwegen. Het is immers niet duidelijk wat de BM25 score zal zijn die toegekend wordt aan een document. Als je hier additief werkt, kan het zijn dat het opgegeven gewicht niet voldoende doorweegt om het gewenste relevantieresultaat te krijgen.
Via de Admin UI in Solr kan je je queries debuggen. Wanneer je de checkbox debugQuery aanvinkt, krijg je in de response de gedetailleerde scoreberekening en de uitleg voor elke score. Zo krijg je inzicht in waarom een bepaald document een specifieke score krijgt bij een zoekopdracht.
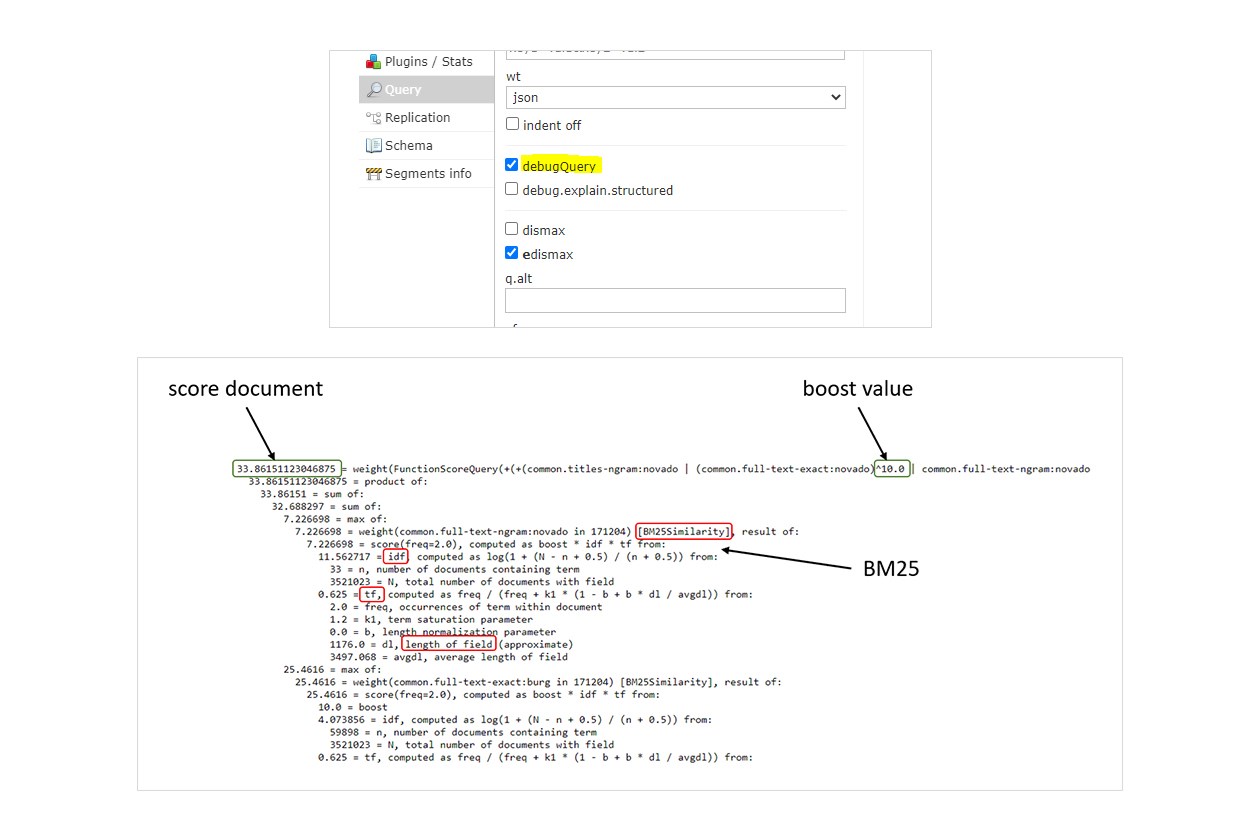
Een doorsnee zoekopdracht van de gebruiker wordt dus doorheen de applicatie aangevuld met verschillende boosting regels volgens de specifieke business case.
Relevantie beheren is niet enkel de taak van de developer maar van het ganse team. Het is een continu proces waarbij verzamelde feedback en inzichten als extra metadata aan de bijhorende documenten in de index toegekend worden. Zo worden de queries verrijkt met boost criteria en kan de eindgebruiker de voor hem relevante informatie eenvoudig vinden.
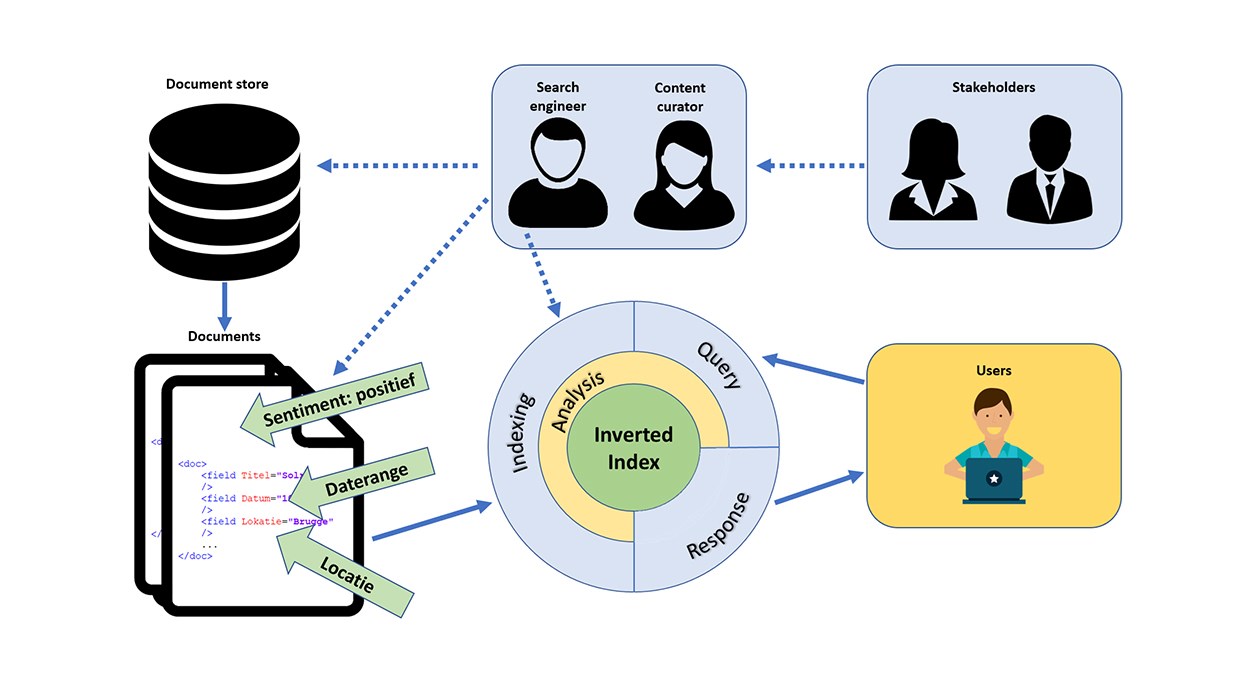
Standaard in Solr zitten er dus al enkele goede technieken die je helpen om relevantie in je toepassingen bij te sturen. Daarnaast kan je ook je eigen systeem of Solr plugins bouwen om op basis van je business case boosting te gaan toepassen, afhankelijk van de context en andere criteria.
Roadmap
De Solr documentatie kan je via deze link terugvinden: https://lucene.apache.org/solr/guide/.
Happy Searching!
Ook op zoek naar de speld in de hooiberg? Het juiste datastukje? We bekijken graag samen hoe we jouw data zo vlot mogelijk doorzoekbaar maken!
Innoveer met ons mee
en onze gloednieuwe cases.