Apache Solr: developer Andy geeft tekst en uitleg
Heb je al gehoord van Solr? Het is een open-source zoekplatform, gebouwd op de Apache Lucene Core, dat we vaak gebruiken voor onze projecten. Developer Andy Tempelaere legt uit wat Solr precies inhoudt.
Zeer krachtige en uitgebreide text zoekmachine
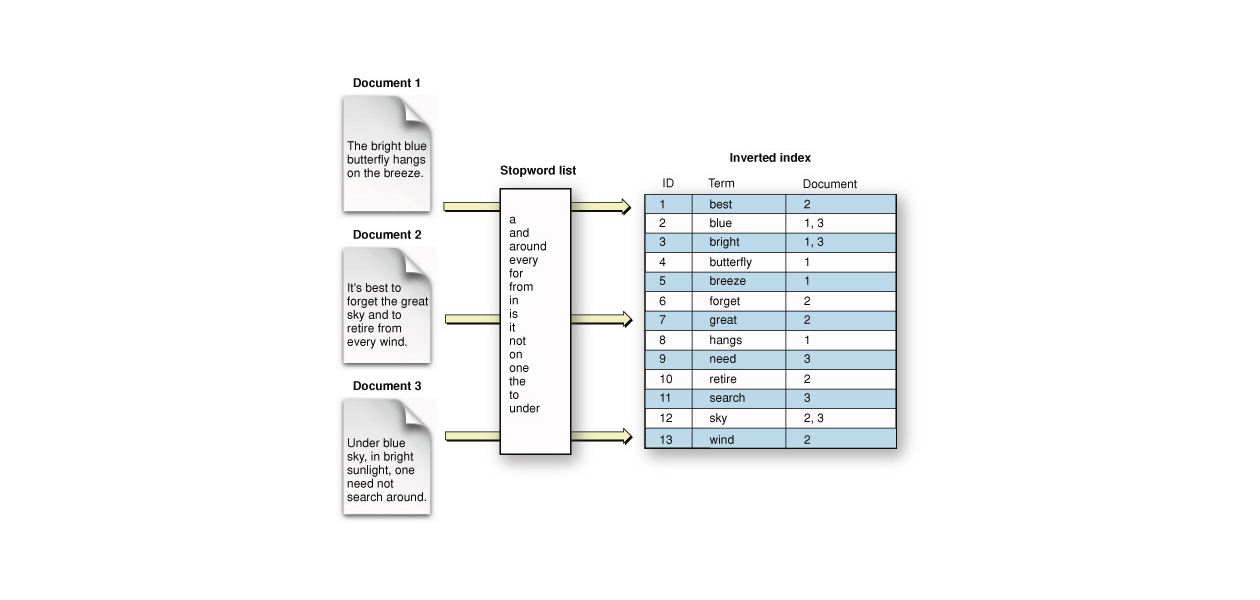
Stel: je hebt één of meerdere boeken of een reeks documenten en je wil te weten komen waar een bepaald woord of een zin voorkomt. Om dit te doen, heb je een index-directory nodig die de paginanummers en/of regelnummers weergeeft waar de gezochte term of zin voorkomt. Dit is precies wat Solr doet.
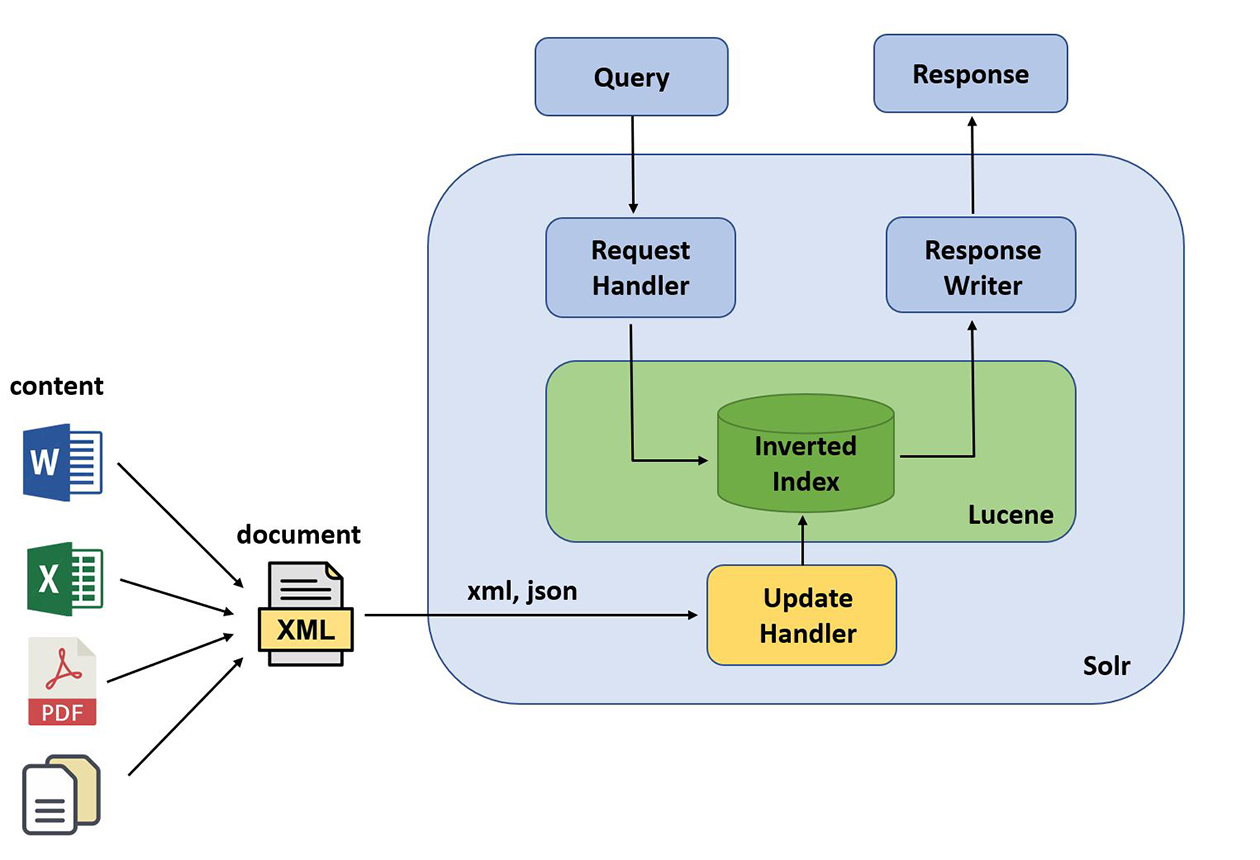
Solr is een krachtige open source search engine die is gebouwd bovenop de Apache Lucene Core. Lucene maakt aan de hand van aangeleverde documenten een Inverted Index aan die bestaat uit de termen en de bijhorende Document-Id's. Solr werkt dus niet zoals een relationele database, waarbij tekstuele opzoekingen enkel gebruik maken van wildcards en eenvoudige normalisatie en bovendien een volledige tablescan vereisen.
Apache Solr gaat als volgt te werk:
- Om te beginnen indexeer je een reeks documenten, bijvoorbeeld nieuwsartikelen.
- Vervolgens zoek je via een specifieke query in Solr.
- Het resultaat is een reeks documenten die relevant zijn volgens je zoekopdracht. Als je bijvoorbeeld zoekt naar de termen ‘Mars’ en ‘Pluto’, raadpleegt Solr zijn Inverted Index en worden de documenten weergeven die deze termen bevatten.
Maar stel dat je 10 documenten terugkrijgt die de woorden Mars en Pluto bevatten, hoe kan je de documenten dan vergelijken en achterhalen welke voor jou het interessantst zijn? Hier spelen termfrequentie, inverse documentfrequentie, documentlength, boosts en verschillende queryparsers een belangrijke rol. Daarnaast bevat Solr verschillende andere features zoals highlighting, faceting, spell checking enz.
In enkele van onze applicaties, zoals het Vanden Broele Connect platform en Kenniswest, maken we gebruik van Solr om de gebruikers op een eenvoudige manier relevante content te laten opzoeken. Solr is zeer schaalbaar en biedt volledig fouttolerante gedistribueerde indexering, zoekopdrachten en analyses.
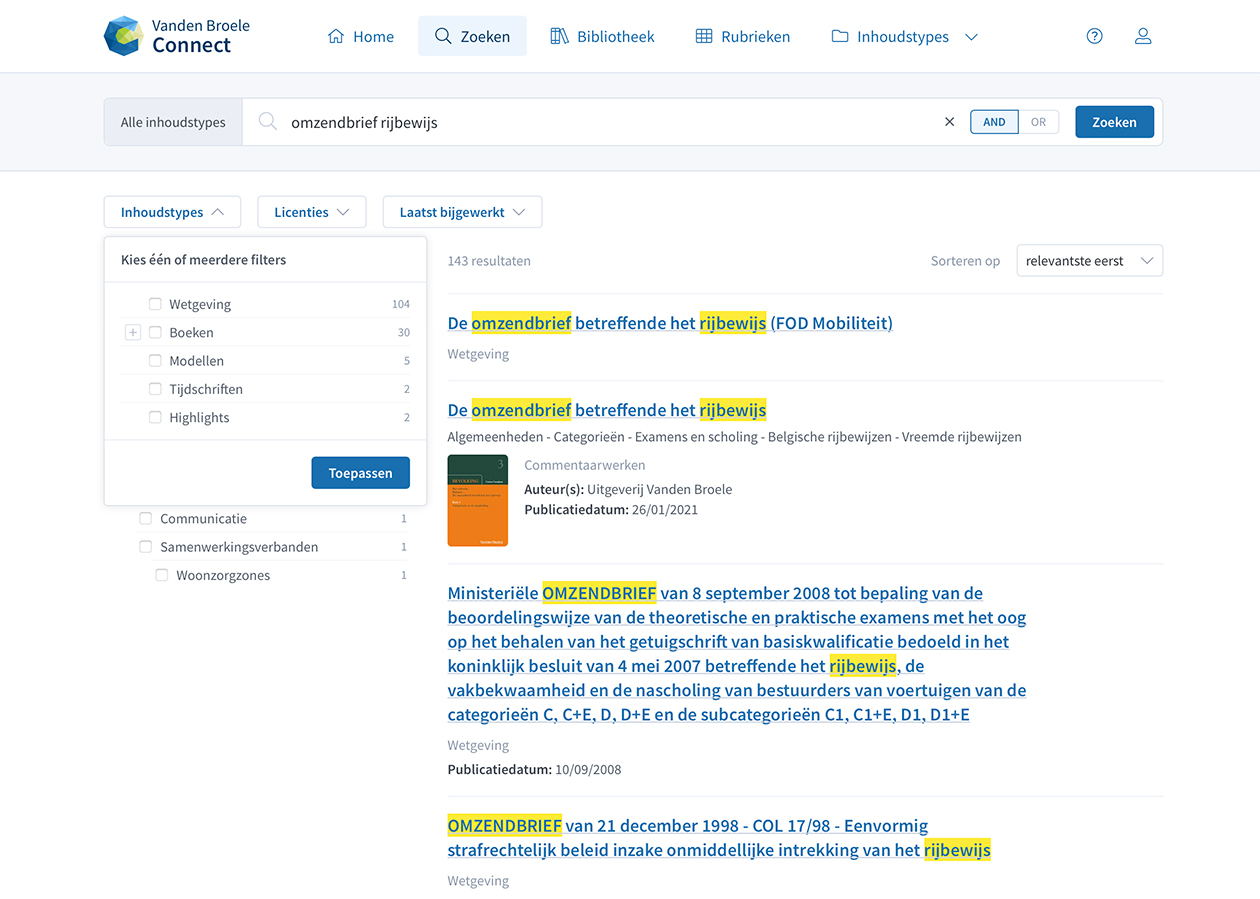
Indexeren
Voor we op zoek gaan naar content in Solr, moet die geconfigureerd worden en voorzien van documenten:
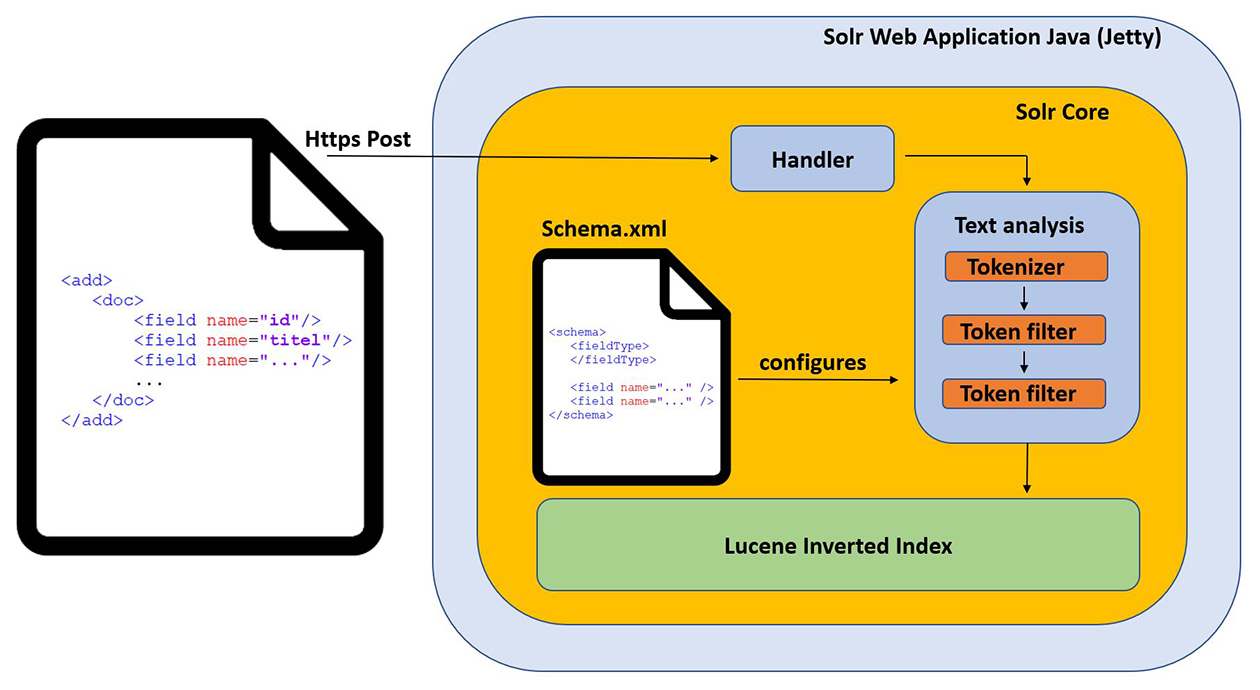
De basisconfiguratie van een Solr instantie bestaat uit:
- xml
- managed-schema.xml
Het solrconfig.xml bestand bevat de configuratie over Solr zelf:
- handlers (select, insert, update…)
- merge strategy
- auto commits
- …
Het managed-schema.xml bestand bevat de configuratie van de documenten die geïndexeerd zullen worden. Als voorbeeld nemen we een nieuwsartikel. Dit bevat enkele velden zoals Titel, Category, ArtikelDatum… Hieronder zie je een voorbeeldconfiguratie van het veld ‘Titel’:

Tijdens het opmaken van van zo’n schema moeten we met de volgende zaken rekening houden, zodat we een index kunnen opbouwen die voldoet aan al onze noden:
- Op welke velden willen we de gebruiker laten zoeken?
- Op welke velden willen we facets toepassen (aggregatie van resultaten)?
- Welke analyzers, tokenizers en filters moeten we gebruiken?
- Komen er verschillende talen in de index?
- Welk type stemming willen we toepassen?
- Op welke velden willen we boosten?
- Welke velden moeten op ‘stored’ komen staan om de originele waarde terug te krijgen?
Tijdens het indexeren en het querien van Solr wordt de data door analyzers gehaald. Een analyzer bevat een pipeline van tokenizers en filters die je zelf kan samenstellen. Kortom, een analyzer neemt een stuk tekst binnen en genereert een tokenstream die in de Inverted Index terechtkomt.
Verschillende tokenizers worden standaard meegeleverd met Solr. De bekendste is de StandardTokenizerFactory. Die splitst de tekst op in tokens, waarbij spaties en leestekens als scheidingsteken worden behandeld. Daarnaast kan je filters opnemen in de analyzers. Het volgende voorbeeld gaat over de LowercaseFilterFactory, die tokens lowercase maakt, en de StopFilterFactory, die tokens verwijdert aan de hand van een vooropgestelde woordenlijst. Het is immers zinloos om termen op te nemen in de index waar de gebruiker toch niet zoekt. Bovendien maakt het de index kleiner.
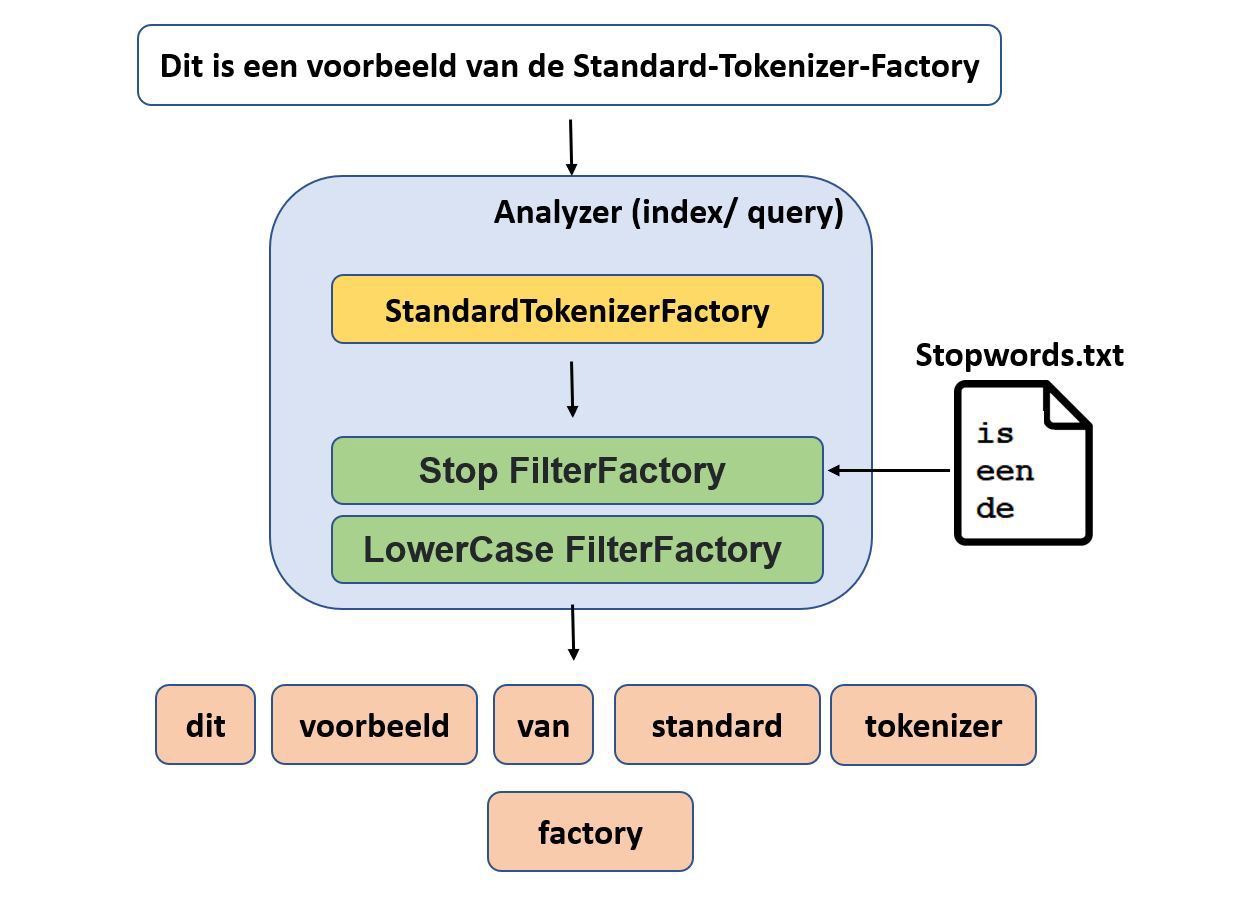
Solr bevat standaard een ruime collectie van tokenizers en filters, die elk een specifieke taak uitvoeren. Het is dus belangrijk om een goede samenstelling te vinden om je documenten optimaal te indexeren. Want hoe beter de index, hoe relevanter de zoekresultaten. Wanneer het schema op punt staat, kan je beginnen met het uploaden (indexeren) van documenten naar de Solr. Documenten versturen naar Solr kan op verschillende manieren. De meest voor de hand liggende zijn via:
- REST Api
- DataImportHandler

In een volgend artikel ga ik dieper in op de relevantie van Solr. Tot binnenkort!
Innoveer met ons mee
en onze gloednieuwe cases.